Insight: The Inference Bottleneck: What NVIDIA's New Inference Chip Means for the Future of HBM (part II)
2 Min Read March 24, 2026
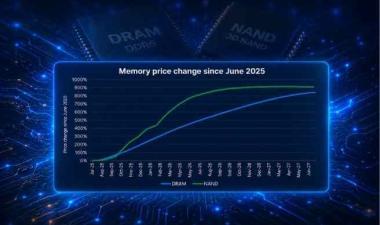
NVIDIA’s Groq deal locks decode acceleration, leaving rival AI chipmakers weighing new paths to handle memory limits and inference bottlenecks through 2026.

NVIDIA's acquisition of Groq locked down the decode acceleration layer before the memory industry could respond. Now every non-NVIDIA accelerator vendor — from Google and AMD to AWS and Meta — faces the same physics problem without access to the solution. Part II maps the five strategic options available to these vendors, from absorbing the bottleneck to partnering with Cerebras or pivoting to processing-in-memory. Essential reading for teams tracking HBM demand dynamics, inference economics, and the shifting architecture of AI accelerator platforms through 2026.
This summary outlines the analysis* found on the TechInsights' Platform.
*Some analyses may only be available with a paid subscription.