Insight: The Inference Bottleneck: What NVIDIA's New Inference Chip Means for the Future of HBM
2 Min Read March 23, 2026
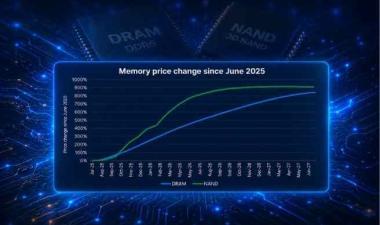
NVIDIA's Groq 3 LPU reveals insights on what a SRAM-dominant and HBM-free inference chip means for the memory supply chain and the future of how AI inference workloads will consume memory.

NVIDIA's $20 billion acquisition of Groq's inference architecture — now integrated as the Groq 3 LPU in the Vera Rubin platform — signals a fundamental shift in how AI inference workloads will consume memory. This insight delivers a first-principles analysis of the decode bottleneck driving this architectural pivot, examines what an SRAM-dominant, HBM-free inference chip means for the memory supply chain, and identifies the opportunity the DRAM industry already has within reach. Essential reading for anyone tracking HBM demand trajectories and AI infrastructure investment through 2026 and beyond.
This summary outlines the analysis* found on the TechInsights' Platform.
*Some analyses may only be available with a paid subscription.