NVIDIA Vera Rubin: Solving the Memory Bottleneck in Large-Context AI Inference
5 Min Read February, 19 2026
NVIDIA’s Vera Rubin Platform marks a decisive shift toward inference workloads and an increasing need for significantly cheaper token generation. Overhauling Blackwell architecture, what challenges does this new co-design network address, and how?

NVIDIA’s Vera Rubin Platform marks a decisive shift toward inference workloads and an increasing need for significantly cheaper token generation. Overhauling Blackwell architecture, what challenges does this new co-design network address, and how?
Not enough storage to decode
As model sizes grow and applications advance from simple chatbots to autonomous AI systems, managing the increasing volume of inference context stored in the KV cache poses a significant challenge.Faster memory access is becoming essential for inference alongside raw computing power.
Vera Rubin’s Inference Context Memory Storage platform leverages the Bluefield-4 DPU power to better handle the workloads required for large context memory. BlueField 4 reduces latency and improves performance and power efficiency by enabling faster memory access via high-speed data network.
The growing need for CPU power
The Vera CPU is optimized for data movement and coherent memory access across the rack, suitable for agentic workloads. Its custom Olympus cores, with 88 cores, feature spatial multithreading, where each core runs two threads for a total of 176. This increases CPU-to-GPU connectivity to 1.8 TB/s, enabling the GPU to offload KV cache memory to DRAM and reuse it later.
In a world where GPU demand is high and capacity is limited, the CPU is becoming integral to running AI applications. Over the long term, we expect demand to be sustained at a 22% CAGR from 25 to 30.
The impact on the larger datacenter market
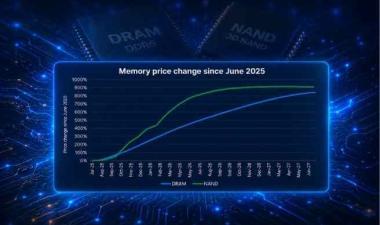
It is becoming increasingly important to keep as much memory as possible close to the CPU/GPU clusters to further optimize the LLM inference context window. Following NVIDIA’s co-design and system integration approach will continue to drive demand for memory. Pushing DRAM and NAND demand through the roof, with ASP and GPU accelerators following with a projected CAGR of 18%.
Explore how large-context AI inference is redefining memory architecture and market dynamics.
Access the full analysis on the TechInsights Platform to evaluate the architectural shifts, memory hierarchy changes, and long-term market implications of large-context AI inference.